Machine Learning
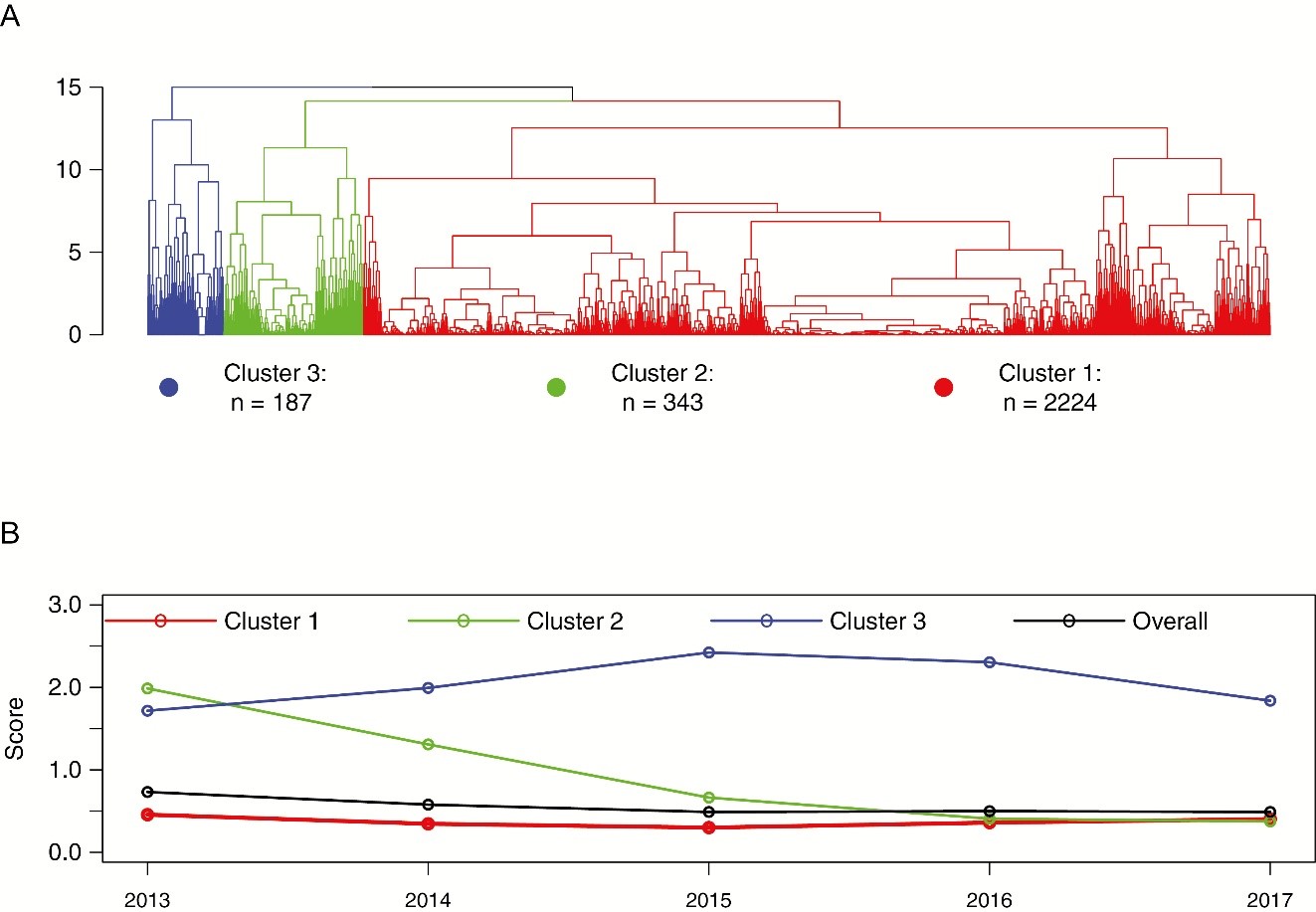
Machine learning (ML) techniques such as hierarchical clustering and random forest analysis offer powerful tools to uncover complex relationships that may be overlooked by traditional epidemiological approaches. These methods can integrate a large variety of different data sources, such as longitudinal data but also high-dimensional data to reveal novel patterns of comorbidities and coinfections in people with HIV. For instance, hierarchical clustering can group individuals based on shared laboratory trajectories or other clinical characteristics, highlighting subpopulations with distinct risk factors or treatment responses. For example, in the project entitled “Self-reported Neurocognitive Impairment in People Living With Human Immunodeficiency Virus (HIV): Characterizing Clusters of Patients With Similar Changes in Self-reported Neurocognitive Impairment, 2013–2017, in the Swiss HIV Cohort Study” we used such hierarchical clustering methods to understand changes in neurocognitive complaints over time (see Figure).
Figure: Clusters derived via unsupervised machine learning algorithms (A) and specific trends observed within these clusters (B).
Random forests, on the other hand, can identify the most predictive variables for disease progression or treatment outcomes, even in the presence of nonlinear interactions and missing data. Further, proteomic data, when combined with clinical and epidemiological variables, enhances the ability to detect subtle biomarkers associated with immune dysregulation, inflammation, or co-infection (e.g., tuberculosis). Machine learning can also help disentangle the bidirectional effects of HIV on other conditions and vice versa, offering more personalized insights into patient care. These approaches complement traditional methods by enabling hypothesis generation from data-rich environments and improving stratification strategies in diverse populations.
Our group applied several machine learning approaches towards getting a deeper understanding of HIV and comorbidities:
- Machine Learning-Based Prediction of Active Tuberculosis in People with HIV using Clinical Data
- Self-reported Neurocognitive Impairment in People Living With Human Immunodeficiency Virus (HIV): Characterizing Clusters of Patients With Similar Changes in Self-reported Neurocognitive Impairment, 2013-2017, in the Swiss HIV Cohort Study